|
Yuming Li 
I am a PhD student at the University of Hong Kong, affiliated with the Musketeers Foundation Institute of Data Science, where I am advised by Andrew Luo. I received my Master's degree in Software Engineering from Peking University, where I worked with Shanghang Zhang. Before that, I earned my Bachelor's degree in Computer Science and Technology from Northwestern Polytechnical University. My research focuses on real-time long video generation, reinforcement learning alignment for diffusion and video generation models, controllable multimodal generation, and embodied world modeling. I am interested in building generative video systems that are fast, controllable, and temporally consistent. |
|
ResearchI work on generative video systems for long-horizon, controllable, and real-time generation. My recent work studies structured RL post-training for diffusion models, streaming audio-visual generation, fast video initialization, and multimodal world models. |
Selected Research |
|
|
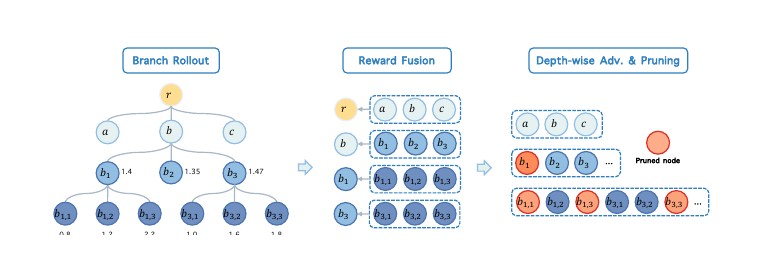
BranchGRPO: Stable and Efficient GRPO with Structured Branching in Diffusion Models
Yuming Li*, Yikai Wang*, Yuying Zhu, Zhongyu Zhao, Ming Lu, Qi She, Shanghang Zhang * Equal contribution ICLR 2026 OpenReview / arXiv / project page / code A structured branching rollout strategy for stable and efficient GRPO training in diffusion models. |
|
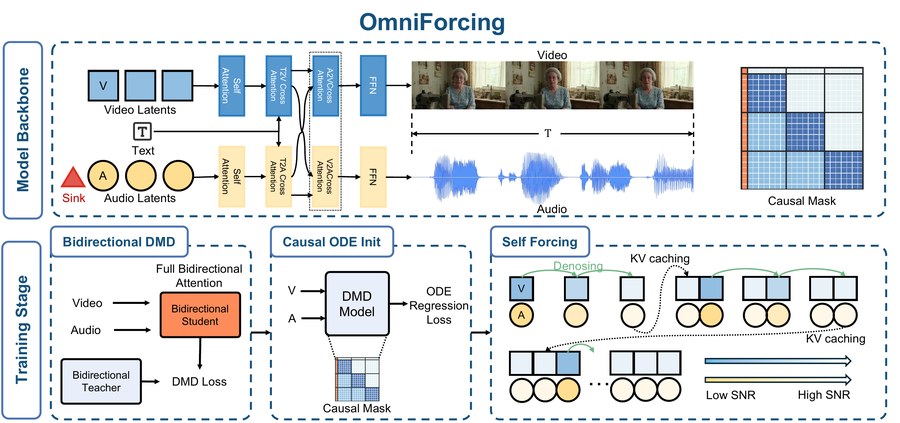
OmniForcing: Unleashing Real-time Joint Audio-Visual Generation
Yaofeng Su*, Yuming Li*, Zeyue Xue, Jie Huang, Siming Fu, Haoran Li, Haoyang Huang, Nan Duan * Equal contribution ECCV 2026 project page / arXiv / code / model A real-time streaming framework for joint audio-visual generation with long-form multimodal consistency. |

|
JoyAI-Echo: Pushing the Frontier of Long Audio-Visual Generation
Echo Team @ Joy Future Academy, JD; Yuming Li is a co-first author listed third Technical Report, 2026 project page / technical report / code / Hugging Face A memory-driven audio-visual generation framework for minute-level coherent video and interactive generation. |
PublicationsAEGPO: Adaptive Entropy-Guided Policy Optimization for Diffusion Models. Yuming Li*, Qingyu Li, Chengyu Bai, Xiangyang Luo, Zeyue Xue, Wenyu Qin, Meng Wang, Yikai Wang, Shanghang Zhang. CVPR 2026 submission. A-ToMe: Adaptive Token Merge for Diffusion Models. Yuming Li*, Ming Lu, Zeyue Li, Xiaowei Chi, Qi She, Shanghang Zhang. arXiv. ASGDiffusion: Parallel High-Resolution Generation with Asynchronous Structure Guidance. Yuming Li*, Peidong Jia, Dongyu Hong, Yixuan Jia, Qi She, Rui Zhao, Ming Lu, Shanghang Zhang. arXiv:2412.06163. FastInit: Fast Noise Initialization for Temporally Consistent Video Generation. Chengyu Bai, Yuming Li*, Zhongyu Zhao, Jintao Chen, Peidong Jia, Qi She, Ming Lu, Shanghang Zhang. arXiv:2506.16119. ManipDreamer3D: Synthesizing Plausible Robotic Manipulation Video with Occupancy-aware 3D Trajectory. Ying Li, Xiaobao Wei, Xiaowei Chi, Zhongyu Zhao, Yuming Li, Hao Wang, Ningning Ma, Sirui Han, Ming Lu. AAAI 2026 poster. |
ExperienceJD.com Exploratory Research Institute / Research Intern, 2025-present. Kuaishou - Kling AI / Research Intern, 2025. Hedra AI / Research Intern, 2025. ByteDance / Research Intern, 2024-2025. Tencent Robotics X / Research Intern, 2024. |
|
Template inspired by Andrew Luo. Last updated July 2026. |